AI 應用收入不等於傳統 SaaS,公司估值取決於成本下降與毛利改善。

TL;DR
一張把 Claude Pro 美國月付約 20 美元拆給模型公司、雲端算力、GPU 折舊、電力和供應鏈的估算圖,正在讓投資者重新討論AI 應用收入到底該怎麼估值。
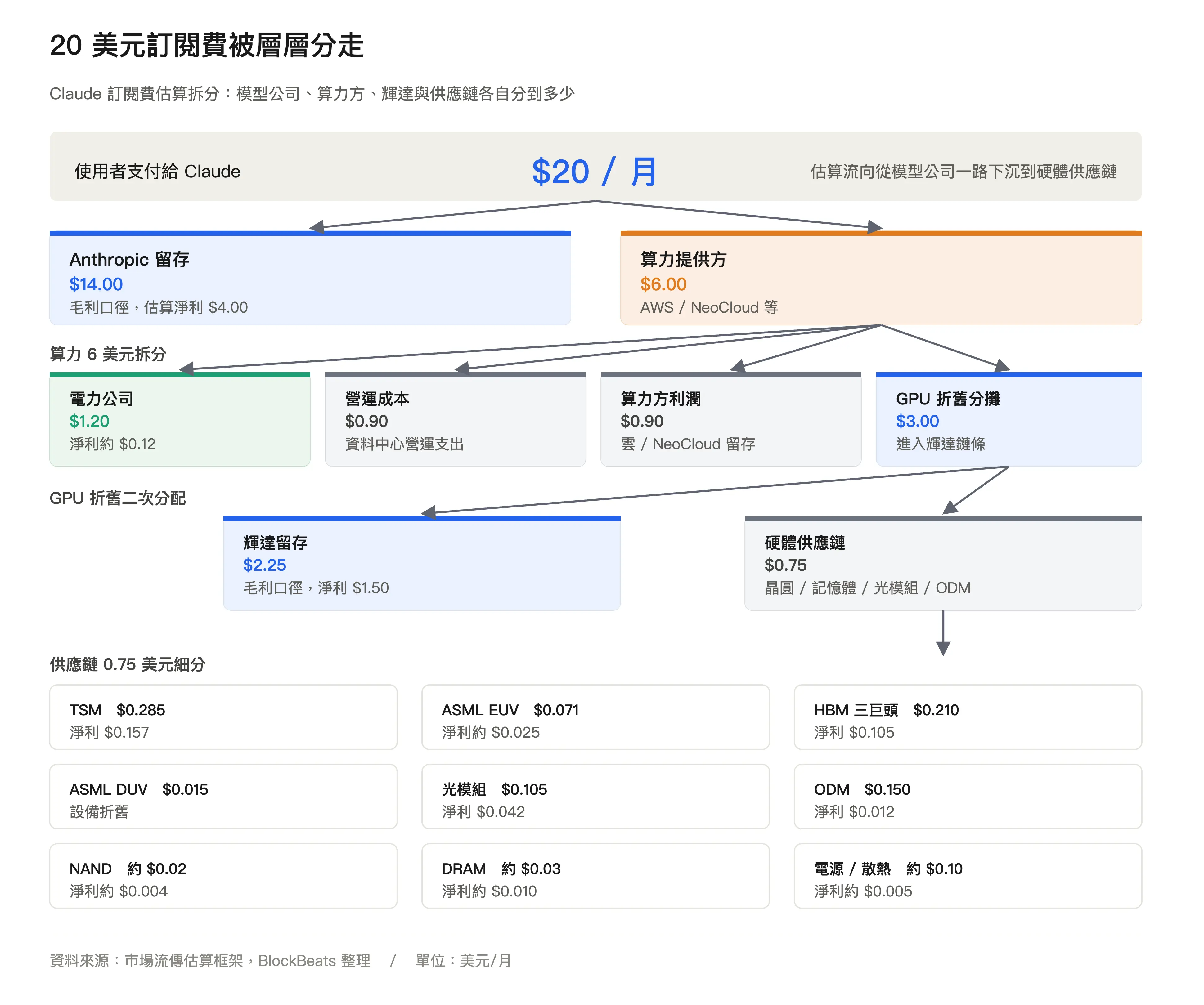
這張圖不是 Anthropic、亞馬遜雲或輝達的官方分帳數據,也不能當成任何一家公司的真實帳本。它的價值在於提出了一個更底層的問題:用戶付給 AI 應用的訂閱費,有多少能像傳統 SaaS 一樣沉澱成軟體毛利?
傳統 SaaS 的估值想像很清楚。軟體寫好後,多賣一個帳號,新增成本通常不高,成熟純軟體公司毛利率常見在 70% 甚至 80% 以上。投資人願意給高倍數,是因為收入規模擴大後,利潤率才有機會繼續抬升。
AI 應用的麻煩在於,使用者每次提問、寫程式碼、分析檔案或呼叫 agent,背後都要消耗 GPU 時間、電力、記憶體頻寬和雲端資源。表面是固定月費,底層卻是一條隨使用量變化的成本鏈。輕度使用者可能是高毛利,重度使用者在可用額度或相關工具套餐內連續跑任務,成本可能迅速上升。
所以,20 美元拆分圖要挑戰的不是某家公司到底拿走幾美元,而是「AI 應用收入是否天然等於 SaaS 收入」。 AI 公司要證明自己值高倍數,不能只證明用戶願意付費,還要證明使用量加權後的毛利率能持續改善。
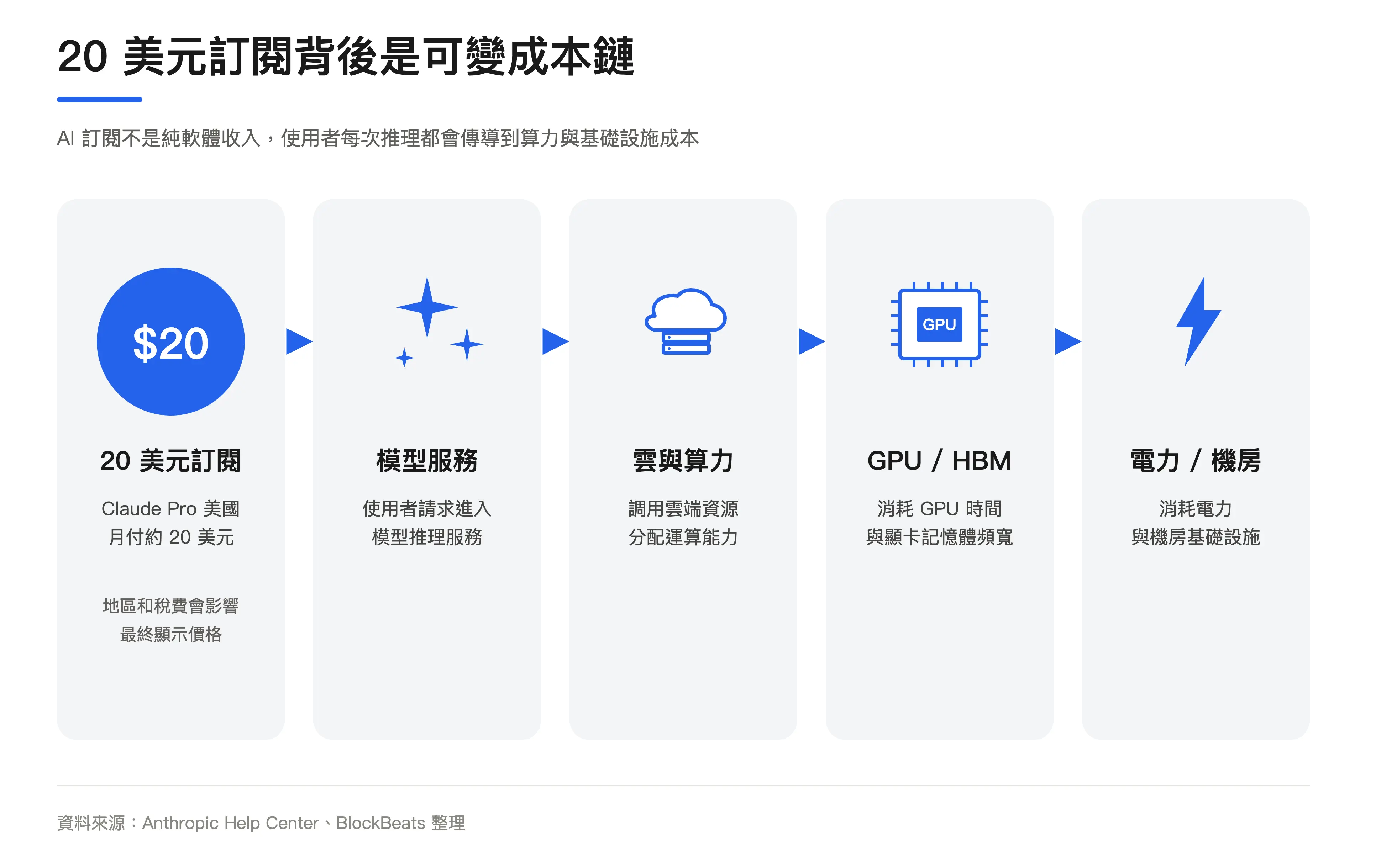
AI 訂閱和普通軟體訂閱最大的不同,是「使用一次」的邊際成本不再接近零。
在傳統 SaaS 裡,一個團隊多開一個帳號,服務商也有伺服器、客服和頻寬成本,但這些成本通常不會隨著每一次點擊線性上升。真正昂貴的是前期研發、銷售和獲客。產品規模化後,新增收入中有相當部分可以留下來。
大模型產品不同。使用者輸入問題,模型產生答案,這個過程叫推理,也就是模型被使用者呼叫時的實際計算。 Token 是模型讀寫文字的基本計量單位。使用者問得越多、上下文越長、產生內容越複雜,消耗的 token 和算力越多。
這就形成了固定訂閱和變動成本之間的衝突。 Claude Pro 美國月付口徑約 20 美元,價格會受地區、稅金和 Anthropic 調整影響。使用者看到的是固定價格,模型公司面對的卻是差異很大的使用行為。有人只是寫郵件和查資料,有人會處理長文檔、跑程式碼任務或呼叫更複雜的自動化流程。
市場流傳的分割圖試圖把這件事具象化:20 美元裡,一部分留給模型公司,一部分支付給雲端和算力提供者。算力成本包含電力、運維、GPU 折舊。 GPU 採購再向上流向輝達、台積電、HBM(高頻寬記憶體)供應商、光模組、ODM 和電力相關企業。
這裡的「GPU 折舊」可以理解為,昂貴 GPU 不是一次性算完成本,而是按使用年限、使用強度或會計口徑慢慢攤到 AI 服務裡。真實分配會受到套餐限額、輕重度使用者比例、雲端廠商內部結算價、預留算力折扣、GPU 使用率和折舊年限影響。平均成本也不等於邊際成本。
投資人真正需要盯住的是方向:AI 應用公司不能只揭露收入成長,還要回答收入成長背後的算力成本是否同步成長。如果使用量擴張快於模型效率提升,訂閱收入越高,毛利壓力可能越明顯。只有效率改善夠快,模型公司才有機會重新接近軟體公司的利潤結構。
現階段,AI 使用量成長更直接流向基礎設施,而不是全部沉澱在應用層。
不管使用者是在 Claude、ChatGPT、Gemini,或是企業內部 agent 裡使用模型,推理最終都要落到算力、電力、記憶體和網路上。應用層可能出現產品更替,底層資源消耗更剛性。只要 AI 使用量持續上升,雲端資本開支、GPU 採購、HBM 需求和資料中心用電就會被拉動。
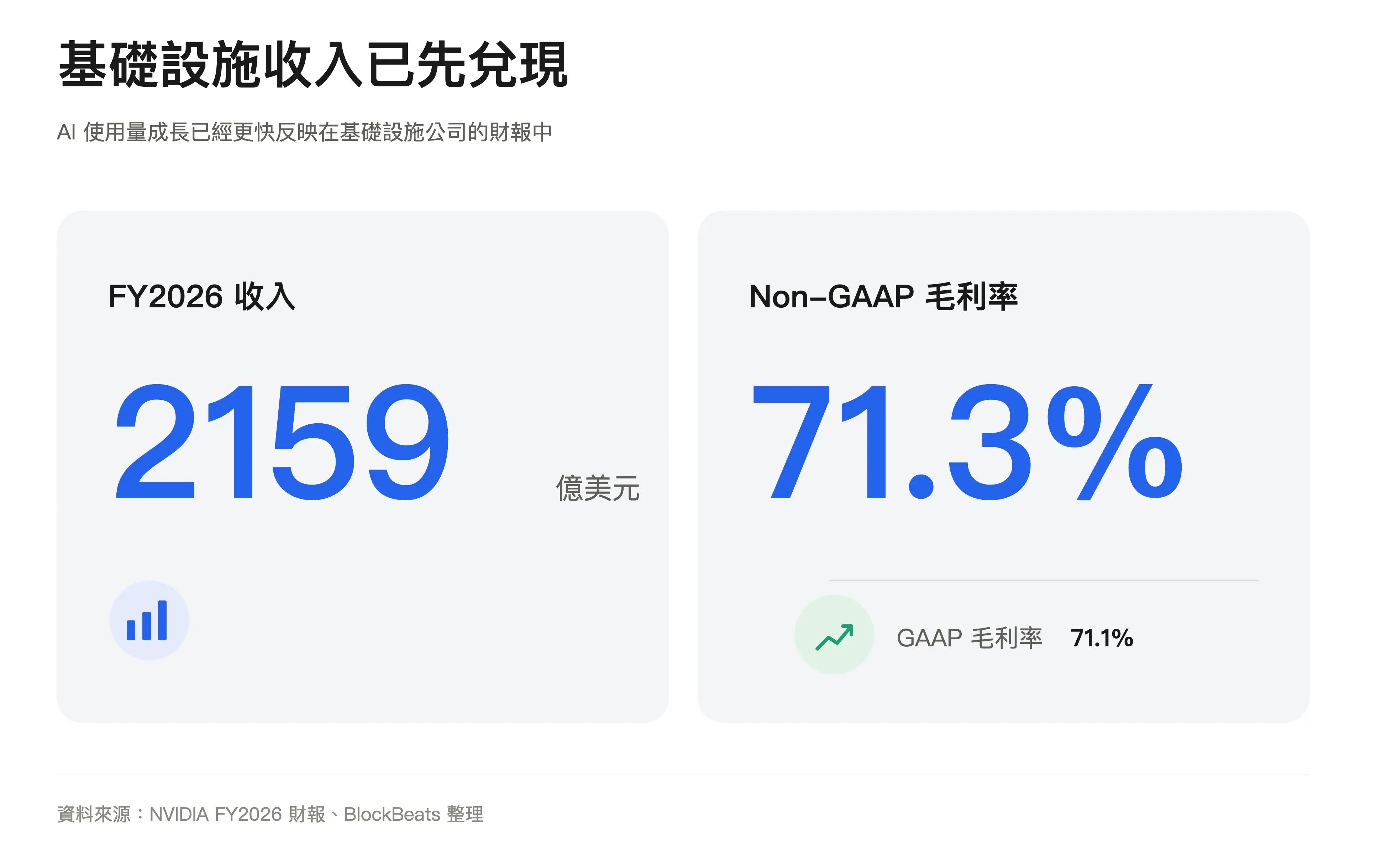
這也是輝達、台積電、SK 海力士等基礎建設鏈持續被市場重估的原因。輝達近年整體毛利率處於高位,FY2026 年度 GAAP 和非 GAAP 毛利率約為 71.1% 和 71.3%,後續季度指引也維持高位。需要注意,個別季度會受特定費用擾動,公開財報也不總是能直接拆出 AI 資料中心的真實毛利結構,但稀缺基礎設施具備定價權這一點已經反映在業績裡。
HBM 是這條鏈上最典型的環節。它不是普通內存,而是 AI 加速器裡支撐高吞吐計算的關鍵部件。模型規模、上下文長度和並發推理需求上升後,AI 晶片對高頻寬記憶體的依賴更強。供應鏈估算顯示,HBM 在新一代 AI 晶片成本中的佔比提高,這也是 SK 海力士、三星、美光在 AI 週期中被重新定價的重要原因。
電力和資料中心也從背景成本變成投資主線。單次普通文字查詢的能耗未必誇張,但複雜 agent、長上下文、程式碼產生和多輪任務會放大計算量。對雲端廠商和資料中心營運商來說,關鍵不是某一次查詢耗電多少,而是海量推理請求持續發生時,集群利用率、電價、冷卻、機房容量和電網接入能力都會變成成本與瓶頸。
基礎設施端的優勢在於業績驗證更快。雲廠商的 AI 資本開支已經發生,輝達收入和毛利體現在財報裡,HBM 廠商訂單和價格也會較快進入利潤表。模型應用層交易的更多是未來預期:訂閱轉換、企業滲透率、API 收入和未來成本曲線下降後的利潤釋放。
軟體投資者和 AI 多頭並非沒有反駁。效率派的核心觀點是,今天推理成本偏高只是早期階段現象,模型優化、快取、小模型、自研晶片和更高集群利用率,會持續壓低單位成本。只要成本下降夠快,AI 應用仍可能回到高毛利軟體邏輯。
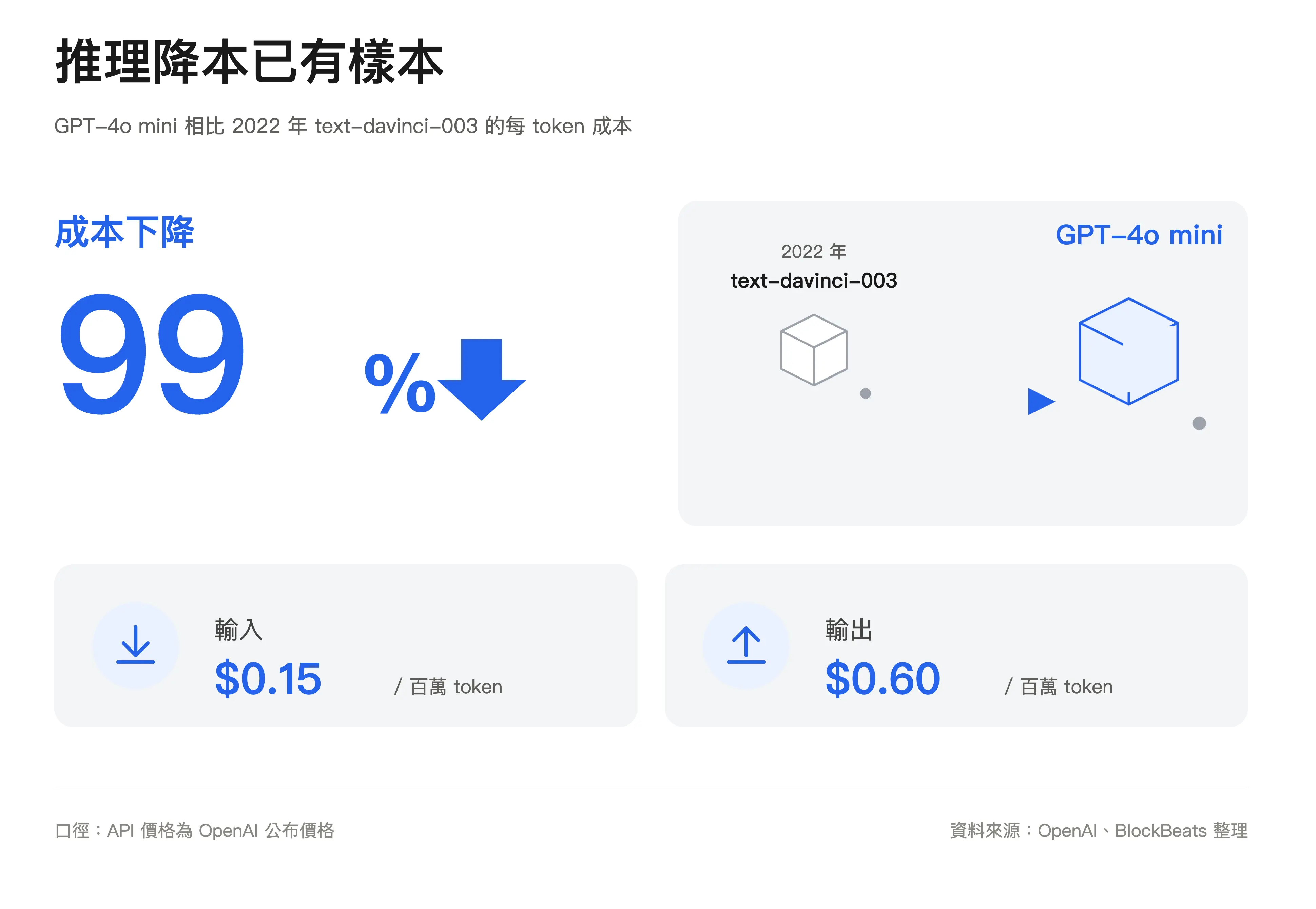
這個反駁有現實基礎。部分主流模型在同等或更高能力下,單位價格已明顯下降。 OpenAI 曾披露,GPT-4o mini 相比早期 text-davinci-003 每 token 成本下降 99%。不同公司節奏並不完全一致,Anthropic 近期更體現為同價升級和模型分層,但產業方向仍是用更低成本提供更強能力。
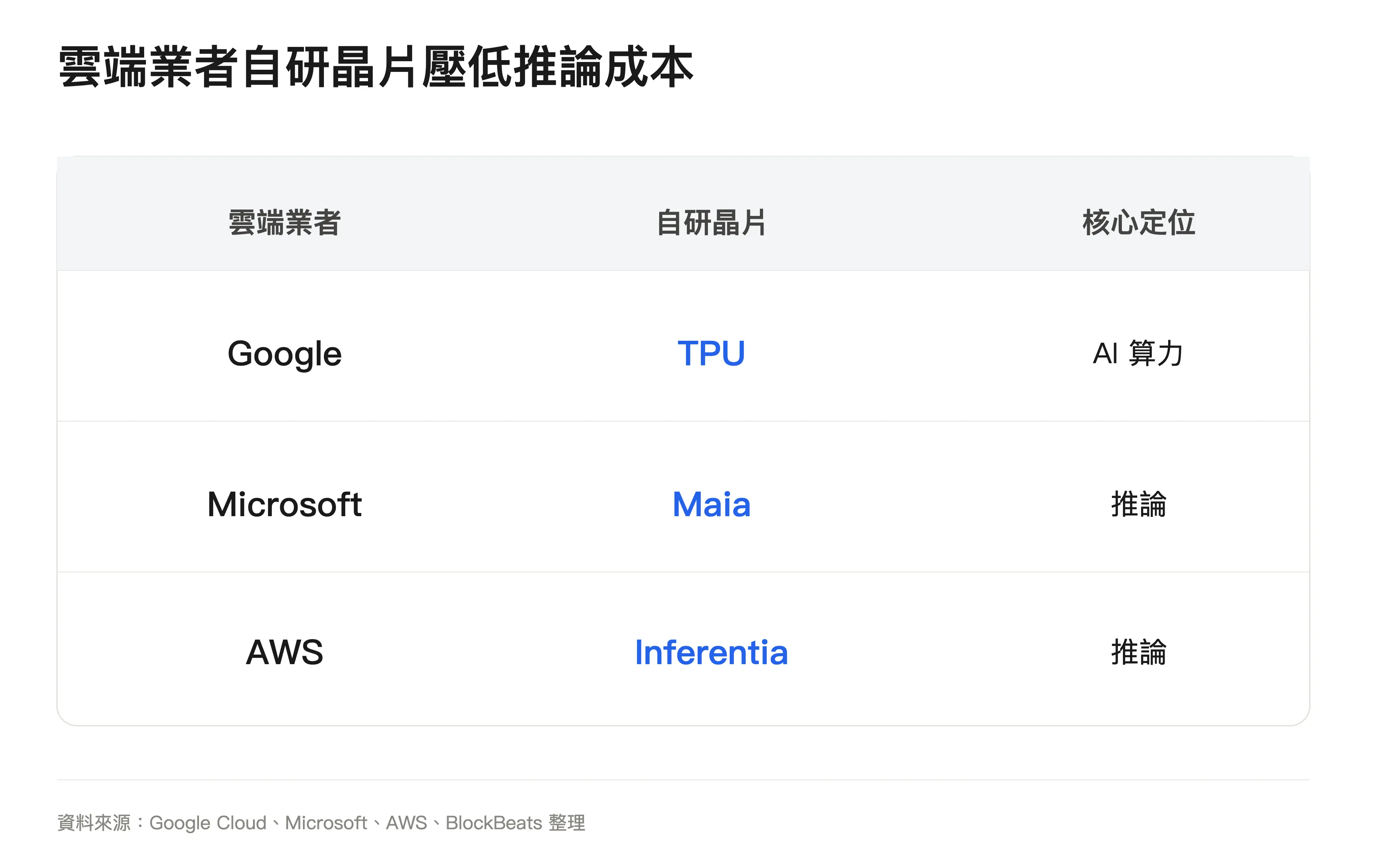
模型公司也有多種辦法改善單位經濟性。簡單任務交給小模型,常見請求透過快取復用,長上下文和複雜任務交給更強模型。雲端廠商則透過自研晶片和集群調度降低單位算力成本。谷歌有 TPU,微軟推出用於推理的 Maia,亞馬遜也在推進 Trainium 和 Inferentia。
如果只看技術進步,AI 應用利潤率確實有改善空間。更便宜的推理、更好的模型路由、更強的壓縮能力,都能讓同樣 20 美元訂閱承載更多使用量。輕度用戶、高價企業套餐、API 分層定價和更嚴格的使用限額,也能改善整體單位經濟性。
難度在於,成本下降不是唯一變數。 AI 應用正在從簡單聊天走向更重的工作負載。過去用戶可能只是問答和改寫文本,現在越來越多需求來自代碼 agent、長文檔處理、視頻和多模態生成、企業自動化流程。這些場景價值更高,消耗也更高。模型越有用,使用者越可能把更複雜、更長的任務交給它。
分歧由此變得更具體:推理成本下降速度,能否超過使用量和任務複雜度的成長。如果單位成本下降很快,但用戶平均消耗成長更快,模型公司的加權毛利率仍會承壓。反過來,如果模型路由、快取、自研晶片和價格分層足夠有效,AI 訂閱可能會逐步擺脫今天的重型成本特徵。
20 美元拆分圖不應被理解為終局。它更像當前階段的估值提醒:當市場還看不到足夠透明的模型公司毛利率數據時,投資人需要給「AI 應用天然等於 SaaS」這個假設打折。
對 OpenAI、Anthropic 這類未上市模型公司來說,外部投資者很難看到完整帳本。融資材料、合作方揭露、雲端成本結構、企業套餐價格、API 收入佔比和使用限制,都會成為判斷線索。真正有價值的數據不是付費用戶有多少,而是輕度用戶和重度用戶各佔多少、企業客戶是否願意為高強度使用付更高價格、雲結算成本是否下降,以及單位推理成本下降能否進入公司毛利率。
上市公司鏈的驗證會更快出現在財報裡。輝達整體毛利率與資料中心營收成長、台積電先進製程與封裝需求、HBM 廠商價格與利潤率、雲端廠商資本開支強度,都會持續反映 AI 使用量是否仍在向基礎設施端傳導。如果這些指標保持強勁,而模型應用層缺乏毛利率改善證據,市場會繼續給予基礎設施更確定的估值溢價。
最終,模型公司要拿回更高估值錨,需要證明的不只是用戶願意付 20 美元,而是這些訂閱費在重度使用之後,仍能留下足夠多的毛利。下一輪定價分歧,很可能不在 ARR 的 headline 數字,而在推理成本、套餐限制和企業付費價格能否同時跑通。
延伸閱讀: